FusionSeq List of programs
From GersteinInfo
(→gfr) |
(→gfrConfidenceValues) |
||
| (69 intermediate revisions not shown) | |||
| Line 6: | Line 6: | ||
This format is defined in the context of [http://rseqtools.gersteinlab.org/ RSEQtools]. More details can be found [http://info.gersteinlab.org/RSEQtools#Data_formats here]. | This format is defined in the context of [http://rseqtools.gersteinlab.org/ RSEQtools]. More details can be found [http://info.gersteinlab.org/RSEQtools#Data_formats here]. | ||
| - | === Gene Fusion Report (GFR) === | + | ===Gene Fusion Report (GFR)=== |
This file format defines the relevant information for each fusion transcript candidate. The rationale is that different filters can be applied to exclude “false positives” artificial fusions starting from an initial set. We also provide a parser that interprets this format allowing the user to propagate easily any changes to this format. For a given fusion candidate, involving gene A and gene B, the basic GFR format requires the following fields: | This file format defines the relevant information for each fusion transcript candidate. The rationale is that different filters can be applied to exclude “false positives” artificial fusions starting from an initial set. We also provide a parser that interprets this format allowing the user to propagate easily any changes to this format. For a given fusion candidate, involving gene A and gene B, the basic GFR format requires the following fields: | ||
| - | # | + | # the ID of the fusion candidate (''id''): typically it contains the sample name and a unique number separated by an underscore. The number is padded with zeros for consistency; |
| - | # SPER, DASPER and RESPER: scoring of the fusion candidate; | + | # ''SPER'', ''DASPER'' and ''RESPER'': scoring of the fusion candidate; |
| - | # Number of inter-transcript reads, i.e. the number of pairs having the ends mapped to the two | + | # Number of inter-transcript reads (''numInter''), i.e. the number of pairs having the ends mapped to the two genes; |
| - | # P-value of the insert size distribution analysis for the fusion transcript. Since we do not know the actual composition of the fusion transcript, we | + | # P-value of the insert size distribution analysis for the fusion transcript. Since we do not know the actual composition of the fusion transcript, we compute the p-value for both directions: AB (where gene A is upstream of gene B - ''pValueAB'') and BA (where gene B is upstream of gene A -- ''pValueBA''); |
| - | # Number of intra-transcript reads for gene A and gene B, respectively, i.e the number of pairs where both ends map to the same gene; | + | # Mean insert-size value of the minimal fusion transcript fragment. As before for the p-values, we compute both AB and BA versions (''interMeanAB'', ''interMeanBA''); |
| - | # The type of the fusion: cis, when both genes are on the same chromosome, or trans, otherwise; | + | # Number of intra-transcript reads for gene A (''numIntra1'') and gene B (''numIntra2''), respectively, i.e the number of pairs where both ends map to the same gene; |
| - | # Name(s) of the transcripts: all the UCSC gene IDs of the isoforms of each gene in the annotation separated by the pipe symbol '|'; | + | # The type of the fusion (''fusionType''): cis, when both genes are on the same chromosome, or trans, otherwise; |
| - | # Chromosome of the genes; | + | # Name(s) of the transcripts (''nameTranscript''): all the UCSC gene IDs of the isoforms of each gene in the annotation separated by the pipe symbol '|'; |
| - | # Strand information; | + | # Chromosome of the genes (''chromosomeTranscript''); |
| - | # Start and end coordinates of the longest transcript for both genes; | + | # Strand information (''strandTranscript''); |
| - | # Number of exons in the composite model for both genes; | + | # Start and end coordinates of the longest transcript for both genes (''startTranscript'', ''endTranscript''); |
| - | # Coordinates of the exons in the composite model: each exon is separated by the pipe symbol '|' and start and end coordinates are comma-separated; | + | # Number of exons in the composite model for both genes (''numExonTranscript''); |
| - | # Exon-pair count: it describes which | + | # Coordinates of the exons in the composite model (''exonCoordinatesTranscript''): each exon is separated by the pipe symbol '|' and start and end coordinates are comma-separated; |
| - | # | + | # Exon-pair count: it describes which elements are connected and corresponding number of inter-transcript reads; |
| + | # interReads: the pair-read type, as well as the exons and the coordinates of the reads joining the two genes. Pair-type, exon number, start and end coordinates are reported as a comma-separated list, with the pipe symbol '|' separating the different pairs. The pair-reads type encodes the different possibilities two reads can be classified to in terms of the gene annotation set: | ||
| + | #* 1 : exon-exon | ||
| + | #* 2 : exon-intron | ||
| + | #* 3 : intron-exon | ||
| + | #* 4 : intron-intron | ||
| + | #* 5 : intron-boundary | ||
| + | #* 6 : exon-boundary | ||
| + | #* 7 : boundary-exon | ||
| + | #* 8 : boundary-intron | ||
| + | #* 9 : boundary-boundary | ||
# Reads of the transcripts: the actual sequence of all the inter-reads. | # Reads of the transcripts: the actual sequence of all the inter-reads. | ||
| - | The GFR format can include additional optional information computed in the subsequent processing. For example, it is possible to add gene symbols and descriptions from the UCSC knownGene annotation set. | + | # Pair-count: a summary of the number of reads for each category and joined exons (see interReads for the category definition). The field reports the pair-reads type, the number of reads, the two exons that are joined by the pair as a comma-separated list. The different pair types are separated by the pipe "|" symbol. |
| + | The GFR format can include additional optional information computed in the subsequent processing. For example, it is possible to add gene symbols (''geneSymbolTranscript'') and descriptions (''descriptionTranscript'') from the UCSC knownGene annotation set. | ||
<center>[[#top|Top]]</center> | <center>[[#top|Top]]</center> | ||
| Line 37: | Line 48: | ||
<center>[[#top|Top]]</center> | <center>[[#top|Top]]</center> | ||
| - | == | + | =Core programs= |
| - | + | ==Fusion detection module== | |
==== geneFusions ==== | ==== geneFusions ==== | ||
| Line 54: | Line 65: | ||
* ''Optional arguments'' | * ''Optional arguments'' | ||
** none | ** none | ||
| + | '''Note''': sample.mrf must include the sequences of the reads. | ||
<center>[[#top|Top]]</center> | <center>[[#top|Top]]</center> | ||
| - | === Mis-alignment filters === | + | ==== gfrClassify ==== |
| + | |||
| + | gfrClassify assign each fusion candidate to a specify category: inter-, intra-chromosomal, read-through, or cis. Please see the [http://dx.doi.org/10.1186/gb-2010-11-10-r104 publication] for a description of these classes. | ||
| + | |||
| + | '''Usage''': | ||
| + | |||
| + | gfrClassify < fileIN.gfr > fileOUT.gfr | ||
| + | |||
| + | * Inputs: Takes a [[#Gene_Fusion_Report_(GFR)|GFR]] file from STDIN | ||
| + | * Outputs: Reports a [[#Gene_Fusion_Report_(GFR)|GFR]] to STDOUT | ||
| + | |||
| + | <center>[[#top|Top]]</center> | ||
| + | |||
| + | ==Filtration cascade module== | ||
| + | ===Mis-alignment filters=== | ||
| + | |||
| + | ---- | ||
| + | |||
==== gfrLargeScaleHomologyFilter ==== | ==== gfrLargeScaleHomologyFilter ==== | ||
It removes potential fusion transcript candidates if the two genes are paralogs. It uses [http://www.treefam.org/ TreeFam] to establish is two genes have similar sequences. | It removes potential fusion transcript candidates if the two genes are paralogs. It uses [http://www.treefam.org/ TreeFam] to establish is two genes have similar sequences. | ||
| Line 67: | Line 96: | ||
* Inputs: [[#Gene_Fusion_Report_(GFR)|GFR]] from STDIN | * Inputs: [[#Gene_Fusion_Report_(GFR)|GFR]] from STDIN | ||
* Outputs: Reports [[#Gene_Fusion_Report_(GFR)|GFR]] to STDOUT | * Outputs: Reports [[#Gene_Fusion_Report_(GFR)|GFR]] to STDOUT | ||
| - | |||
| - | |||
| - | |||
| - | |||
<center>[[#top|Top]]</center> | <center>[[#top|Top]]</center> | ||
| Line 80: | Line 105: | ||
'''Usage''': | '''Usage''': | ||
| - | gfrSmallScaleHomologyFilter < fileIN.gfr >fileOUT.gfr | + | gfrSmallScaleHomologyFilter < fileIN.gfr > fileOUT.gfr |
* Inputs: [[#Gene_Fusion_Report_(GFR)|GFR]] from STDIN | * Inputs: [[#Gene_Fusion_Report_(GFR)|GFR]] from STDIN | ||
* Outputs: Reports [[#Gene_Fusion_Report_(GFR)|GFR]] to STDOUT | * Outputs: Reports [[#Gene_Fusion_Report_(GFR)|GFR]] to STDOUT | ||
| - | |||
| - | |||
| - | |||
| - | |||
<center>[[#top|Top]]</center> | <center>[[#top|Top]]</center> | ||
| - | ==== | + | ==== gfrRepeatMaskerFilter ==== |
| - | + | Some reads may be aligned to repetitive regions in the genome, due to the low sequence complexity of those regions and may result in artificial fusion candidates. This filter removes reads mapped to those regions. If the number of reads left if less than a threshold, the candidate is removed. | |
'''Usage''': | '''Usage''': | ||
| - | + | gfrRepeatMaskerFilter repeatMasker.interval minNumberOfReads < fileIN.gfr > fileOUT.gfr | |
| - | * Inputs: from STDIN | + | * Inputs: [[#Gene_Fusion_Report_(GFR)|GFR]] from STDIN |
* Outputs: Reports [[#Gene_Fusion_Report_(GFR)|GFR]] to STDOUT | * Outputs: Reports [[#Gene_Fusion_Report_(GFR)|GFR]] to STDOUT | ||
* ''Required arguments'' | * ''Required arguments'' | ||
| - | ** | + | ** repeatMasker.interval - the interval file with the coordinates of the repetitive regions |
| - | ** | + | ** minNumberOfRead - minimum number of reads overlapping the repetitive regions in order to remove the candidate |
| - | + | ||
| - | + | ||
| - | + | ||
| - | + | ||
<center>[[#top|Top]]</center> | <center>[[#top|Top]]</center> | ||
| - | ==== | + | ===Random pairing of transcript fragments=== |
| - | + | ---- | |
| + | |||
| + | ==== gfrAbnormalInsertSizeFilter ==== | ||
| + | |||
| + | gfrAbnormalInsertSizeFilter removes candidates with an insert-size bigger than the normal insert-size. The fusion candidate insert-size is computed on the ''minimal fusion transcript fragment''. | ||
'''Usage''': | '''Usage''': | ||
| - | + | gfrAbnormalInsertSizeFilter pvalueCutOff < fileIN.gfr > fileOUT.gfr | |
| - | * Inputs: from STDIN | + | * Inputs: [[#Gene_Fusion_Report_(GFR)|GFR]] from STDIN |
* Outputs: Reports [[#Gene_Fusion_Report_(GFR)|GFR]] to STDOUT | * Outputs: Reports [[#Gene_Fusion_Report_(GFR)|GFR]] to STDOUT | ||
* ''Required arguments'' | * ''Required arguments'' | ||
| - | ** | + | ** pvalueCutOff - the p-value threshold above which we keep the fusion transcript candidates |
| - | + | ||
| - | + | ||
| - | + | ||
| - | < | + | <center>[[#top|Top]]</center> |
| + | |||
| + | ===Combination of mis-alignment and random pairing=== | ||
| + | |||
| + | ---- | ||
| + | |||
| + | ==== gfrRibosomalFilter ==== | ||
| + | |||
| + | gfrRibosomalFilter removes candidates that have similarity with ribosomal genes. The rationale is that reads coming from highly expressed genes, such as ribosomal genes, are more likely to be mis-aligned and assigned to a different genes. | ||
| + | |||
| + | '''Usage''': | ||
| + | |||
| + | gfrRibosomalFilter < fileIN.gfr > fileOUT.gfr | ||
| + | |||
| + | * Inputs: [[#Gene_Fusion_Report_(GFR)|GFR]] from STDIN | ||
| + | * Outputs: Reports [[#Gene_Fusion_Report_(GFR)|GFR]] to STDOUT | ||
<center>[[#top|Top]]</center> | <center>[[#top|Top]]</center> | ||
| - | ==== | + | ==== gfrExpressionConsistencyFilter ==== |
| - | + | It removes candidates that have a higher number of chimeric PE reads than PE reads aligned to the corresponding individual genes. This filter would only consider cases where the chimeric reads are mapped to introns of the two genes. | |
'''Usage''': | '''Usage''': | ||
| - | + | gfrExpressionConsistencyFilter < fileIN.gfr > fileOUT.gfr | |
| - | * Inputs: from STDIN | + | * Inputs: [[#Gene_Fusion_Report_(GFR)|GFR]] from STDIN |
* Outputs: Reports [[#Gene_Fusion_Report_(GFR)|GFR]] to STDOUT | * Outputs: Reports [[#Gene_Fusion_Report_(GFR)|GFR]] to STDOUT | ||
| - | |||
| - | |||
| - | |||
| - | |||
| - | |||
| - | < | + | <center>[[#top|Top]]</center> |
| + | |||
| + | ===Other filters=== | ||
| + | |||
| + | ---- | ||
| + | |||
| + | ==== gfrPCRFilter ==== | ||
| + | |||
| + | gfrPCRFilter removes candidates with the same read over-represented, yielding to a “spike-in-like” signal, i.e. a narrow signal with a high peak. | ||
| + | |||
| + | '''Usage''': | ||
| + | |||
| + | gfrPCRFilter offsetCutoff minNumUniqueRead | ||
| + | * Inputs: [[#Gene_Fusion_Report_(GFR)|GFR]] from STDIN | ||
| + | * Outputs: Reports [[#Gene_Fusion_Report_(GFR)|GFR]] to STDOUT | ||
| + | * ''Required arguments'' | ||
| + | ** offsetCutoff - the minimum number of different starting positions | ||
| + | ** minNumUniqueRead - the minimum number of unique reads required to include a candidate | ||
<center>[[#top|Top]]</center> | <center>[[#top|Top]]</center> | ||
| - | ==== | + | ==== gfrAnnotationConsistencyFilter ==== |
| - | + | It removes candidates involving genes with specific description, such as ribosomal, pseudogenes, etc. | |
'''Usage''': | '''Usage''': | ||
| - | + | gfrAnnotationConsistencyFilter string < fileIN.gfr > fileOUT.gfr | |
| - | * Inputs: from STDIN | + | * Inputs: [[#Gene_Fusion_Report_(GFR)|GFR]] from STDIN |
* Outputs: Reports [[#Gene_Fusion_Report_(GFR)|GFR]] to STDOUT | * Outputs: Reports [[#Gene_Fusion_Report_(GFR)|GFR]] to STDOUT | ||
* ''Required arguments'' | * ''Required arguments'' | ||
| - | ** | + | ** string - a string identifying the element to remove, ex. pseudogene |
| - | + | ||
| - | + | ||
| - | + | ||
| - | + | ||
| - | + | ||
<center>[[#top|Top]]</center> | <center>[[#top|Top]]</center> | ||
| - | ==== | + | ==== gfrProximityFilter ==== |
| - | + | It removes candidates that are likely due to mis-annotation of the 5' or 3' ends of the genes. | |
'''Usage''': | '''Usage''': | ||
| - | + | gfrProximityFilter offset < fileIN.gfr > fileOUT.gfr | |
| - | * Inputs: from STDIN | + | * Inputs: [[#Gene_Fusion_Report_(GFR)|GFR]] from STDIN |
* Outputs: Reports [[#Gene_Fusion_Report_(GFR)|GFR]] to STDOUT | * Outputs: Reports [[#Gene_Fusion_Report_(GFR)|GFR]] to STDOUT | ||
* ''Required arguments'' | * ''Required arguments'' | ||
| - | ** | + | ** offset - the minimum distance (in nucleotides) between the two genes to keep the candidate |
| - | + | ||
| - | + | ||
| - | + | ||
| - | + | ||
| - | + | ||
<center>[[#top|Top]]</center> | <center>[[#top|Top]]</center> | ||
| - | ==== | + | ==== gfrBlackListFilter ==== |
| - | + | It removes candidates specified by the user in a file | |
'''Usage''': | '''Usage''': | ||
| - | + | gfrBlackListFilter blackList.txt < fileIN.gfr > fileOUT.gfr | |
| - | * Inputs: from STDIN | + | * Inputs: [[#Gene_Fusion_Report_(GFR)|GFR]] from STDIN |
* Outputs: Reports [[#Gene_Fusion_Report_(GFR)|GFR]] to STDOUT | * Outputs: Reports [[#Gene_Fusion_Report_(GFR)|GFR]] to STDOUT | ||
* ''Required arguments'' | * ''Required arguments'' | ||
| - | ** | + | ** blackList.txt - the file with the candidates to remove. The format of this files is a simple two-column tab-delimited file with describing the two gene symbols. For example: |
| - | + | <pre> | |
| - | + | LOC388160 LOC388161 | |
| - | + | LOC388161 LOC388161 | |
| - | + | LOC440498 LOC440498 | |
| - | < | + | </pre> |
<center>[[#top|Top]]</center> | <center>[[#top|Top]]</center> | ||
| - | ==== | + | ==== gfrSpliceJunctionFilter ==== |
| - | + | It removes candidates if the reads can be aligned to a splice junction library. '''NB''': this filter should be used only if the alignment was not performed against a splice junction library. | |
'''Usage''': | '''Usage''': | ||
| - | + | gfrSpliceJunctionFilter splice_junction_library < fileIN.gfr > fileOUT.gfr | |
| - | * Inputs: from STDIN | + | * Inputs: [[#Gene_Fusion_Report_(GFR)|GFR]] from STDIN |
* Outputs: Reports [[#Gene_Fusion_Report_(GFR)|GFR]] to STDOUT | * Outputs: Reports [[#Gene_Fusion_Report_(GFR)|GFR]] to STDOUT | ||
* ''Required arguments'' | * ''Required arguments'' | ||
| - | ** | + | ** splice_junction_library - the splice_junction_library in 2bit format |
| - | + | ||
| - | + | <center>[[#top|Top]]</center> | |
| - | ** | + | |
| + | |||
| + | ==== gfrMitochondrialFilter ==== | ||
| + | |||
| + | It removes candidates including a mitochondrial gene. '''NB''': this filter should be used only if the alignment was performed against a gene annotation set with mitochondrial genes. | ||
| + | |||
| + | '''Usage''': | ||
| + | |||
| + | gfrMitochondrialFilter < fileIN.gfr > fileOUT.gfr | ||
| + | |||
| + | * Input: [[#Gene_Fusion_Report_(GFR)|GFR]] from STDIN | ||
| + | * Output: Reports the filtered [[#Gene_Fusion_Report_(GFR)|GFR]] to STDOUT | ||
| - | |||
<center>[[#top|Top]]</center> | <center>[[#top|Top]]</center> | ||
| - | ==== | + | ===Scoring the candidates=== |
| - | + | ---- | |
| + | |||
| + | ==== gfrConfidenceValues ==== | ||
| + | |||
| + | gfrConfidenceValues computes the scores SPER, DASPER, and RESPER for each candidate. SPER is the number of '''S'''upportive '''PE R'''eads per candidates, i.e. the normalized number of inter-transcript reads. | ||
| + | |||
| + | <math>SPER=\frac {m}{N_{mapped}}*10^6</math> | ||
| + | |||
| + | where <math>m</math> is the number of inter-transcript reads, i.e. PE-reads connecting two different genes. | ||
| + | |||
| + | DASPER ('''D'''ifference between the observed and the '''A'''nalytically computed '''SPER''') and RESPER ('''R'''atio between the observed SPER and the '''E'''mpirically computed '''SPER''') compare the observed SPER with two slightly different ways to compute the expectation. | ||
| + | Please find at [http://genomebiology.com/2010/11/10/R104/abstract Genome Biology, 2010;11:R104] more information about those scores. | ||
'''Usage''': | '''Usage''': | ||
| - | + | gfrConfidenceValues prefix | |
| + | * Input: [[#Gene_Fusion_Report_(GFR)|GFR]] from STDIN | ||
| + | * Output: Reports [[#Gene_Fusion_Report_(GFR)|GFR]] to STDOUT | ||
| + | * ''Required arguments'' | ||
| + | ** prefix - the prefix of the .meta file | ||
| + | '''Note''': gfrConfidenceValues expects that the file prefix.meta is available. This tab-delimited file includes some meta information about the MRF dataset. The minimum required set of information is the number of mapped reads with the following syntax as an example: | ||
| + | Mapped_reads 236549456 | ||
| + | This represent the number of PE reads that were mapped. It is possible to determine this number by counting the number of lines in the [[#Mapped Read Format (MRF)|MRF]] file. For example: | ||
| + | grep -v AlignmentBlocks file.mrf | grep -v "#" | wc -l | ||
| - | * | + | A one-line command to generate this is: |
| - | * | + | $ MAPPED=$(grep -v "AlignmentBlock" file.mrf | grep -v "#" | wc -l); printf "Mapped_reads\t%d\n" $MAPPED > file.meta |
| + | |||
| + | <center>[[#top|Top]]</center> | ||
| + | |||
| + | ==== gfrConfidenceValueTranscript [deprecated]==== | ||
| + | |||
| + | gfrConfidenceValueTranscript computes LSPER ('''L'''ocal '''SPER''') as the number of inter-transcript PE reads supporting the fusion divided by the average gene expression value. However, since in many cases, only one allele contributes to the fusion transcript, the expression of the fusion transcript may not correlate with the expression of the genes generating it. Please find at [http://genomebiology.com/2010/11/10/R104/abstract Genome Biology 2010;11:R104] more details about why this score may impair the correct ranking of the candidates (see Additional file 1, text and Figure S6). | ||
| + | |||
| + | '''Usage''': | ||
| + | |||
| + | gfrConfidenceValueTranscript prefix | ||
| + | * Input: [[#Gene_Fusion_Report_(GFR)|GFR]] from STDIN | ||
| + | * Output: Reports [[#Gene_Fusion_Report_(GFR)|GFR]] to STDOUT | ||
* ''Required arguments'' | * ''Required arguments'' | ||
| - | ** prefix - the | + | ** prefix - the prefix of the .composite.expression file |
| - | ** | + | '''Note''': gfrConfidenceValueTranscript expects that the file prefix.composite.expression is available. This file includes the expression values for the genes that are part of the transcript. The best way to compute is by using [http://rseqtools.gersteinlab.org/ RSEQtools], using [[RSEQtools#mrfQuantifier|mrfQuantifier]], e.g.: |
| - | * '' | + | mrfQuantifier knownGeneTranscriptCompositeModel.txt multipleOverlap < prefix.mrf > prefix.composite.expression |
| - | ** | + | where knowGeneTranscriptCompositeModel.txt is the interval file representing the UCSC knownGenes library. |
| + | <center>[[#top|Top]]</center> | ||
| + | |||
| + | ==Junction-sequence identification module== | ||
| + | |||
| + | ==== gfr2bpJunctions ==== | ||
| + | |||
| + | It generates the splice junction library and two files to be run with a cluster to perform the indexing and the mapping in parallel. | ||
| + | |||
| + | '''Usage''': | ||
| + | |||
| + | gfr2bpJunctions <file.gfr> <tileSize> <sizeFlankingRegion> <minDASPER> | ||
| + | |||
| + | * Input: file.gfr - [[#Gene_Fusion_Report_(GFR)|GFR]] file (not from STDIN) | ||
| + | * Outputs: Two files with all the jobs to be run on a cluster: | ||
| + | ** file_joblist1.txt: the instructions to index the library and align the reads to the junction library. | ||
| + | ** file_joblist2.txt: the instructions to aggregate the results of the alignment. | ||
| + | * Required parameters: | ||
| + | ** tileSize: the number of nucleotides in each tile. For example, a 50nt read may be aligned to a 80nt junction, thus tileSize would be 40. | ||
| + | ** sizeFlankingRegions: the size, in nucleotides, of the flanking region around the exons. | ||
| + | ** minDASPER: the minimum DASPER values for which the breakpoint analysis is performed. | ||
| + | |||
| + | <center>[[#top|Top]]</center> | ||
| + | |||
| + | ==== validateBpJunctions ==== | ||
| + | |||
| + | It validates the junctions, i.e. excludes those junctions with sequence similarity to the other regions of the genome. | ||
| + | |||
| + | '''Usage''': | ||
| + | |||
| + | validateBpJunctions < fileIN.bp > fileOUT.bp | ||
| + | |||
| + | * Input: a [[#Breakpoint data format (BP)|BP]] file from STDIN | ||
| + | * Output: a [[#Breakpoint data format (BP)|BP]] to STDOUT | ||
| + | |||
| + | <center>[[#top|Top]]</center> | ||
| + | |||
| + | ==== bpFilter ==== | ||
| + | |||
| + | It filters some of the junctions because of number of reasons (see parameters). | ||
| + | |||
| + | '''Usage''': | ||
| + | |||
| + | bpFilter <minNumReads> <minNumUniqueOffsets> <minNumReadsForKS> <pValueCutoffForKS> <numPossibleOffsets> | ||
| + | |||
| + | * Input: [[#Breakpoint Data Format (BP)|BP]] file from STDIN | ||
| + | * Output: [[#Breakpoint Data Format (BP)|BP]] file to STDOUT | ||
| + | * Required parameters | ||
| + | ** minNumReads: minimum number of reads aligned to the junction to be kept | ||
| + | ** minNumUniqueOffsets: minimum number of unique reads aligned to the junction to avoid PCR artifacts | ||
| + | ** minNumReadsForKS: minimum number of reads to perform a Kolmogorov-Smirnov (KS) test. This would compare the reads distribution with a uniform one. However, only if there are sufficient reads this test can be performed. | ||
| + | ** pValueCutoffForKS: the pvalue cut-off if a KS test is used | ||
| + | ** numPossibleOffsets: number of possible offsets, i.e. starting positions of the reads | ||
| + | <center>[[#top|Top]]</center> | ||
| + | |||
| + | ==== bp2wig ==== | ||
| + | |||
| + | It generates a signal track from the reads aligned to the junction. | ||
| + | |||
| + | '''Usage''': | ||
| + | |||
| + | bp2wig file.bp | ||
| + | |||
| + | * Input: [[#Breakpoint Data Format (BP)|BP]] file (not from STIDIN) | ||
| + | * Output: WIGGLE files showing the support of the junction | ||
| + | |||
| + | <center>[[#top|Top]]</center> | ||
| + | |||
| + | ==== bp2alignment ==== | ||
| + | |||
| + | It generates a text representation of the reads aligned to the junction. | ||
| + | |||
| + | '''Usage''': | ||
| + | |||
| + | bp2alignment | ||
| + | |||
| + | * Input: [[#Breakpoint Data Format (BP)|BP]] file from STDIN | ||
| + | * Output: an text file to STDOUT reporting the aligned read to the junction. For example: | ||
| + | <pre> | ||
| + | Tile 1: chr21:38717312-38717353 | ||
| + | Tile 2: chr21:41801877-41801918 | ||
| + | Number of reads spanning breakpoint: 5 | ||
| + | |||
| + | |||
| + | AGGAGGGTTC CTGCCGCGCTCCAGGCGGCGCTCCCCGCCCCTCGCCCTCCG | ||
| + | ATTCATCAGGAGAGTTC CTACCGCGCTCCAGGCGGCGCTCCCCGCCCCTCG | ||
| + | CCACACTGCATTCATCAGGAGAGTTC CTGCCGCGCTCCAGGCGGCGCTCCC | ||
| + | CTTCCCGCCTTCGGCCACACTGCATTCATCAGGAGAGTTC CTGCCGCGCTC | ||
| + | CTTCCCGCCTTCGGCCACACTGCATTCATCAGGAGAGTTC CTGCCGCGCTC | ||
| + | TCTTCCCGCCTTTGGCCACACTGCATTCATCAGGAGAGTTC CTGCCGCGCTCCAGGCGGCGCTCCCCGCCCCTCGCCCTCCG | ||
| + | </pre> | ||
| + | |||
| + | <center>[[#top|Top]]</center> | ||
| + | |||
| + | ==== bowtie2bp ==== | ||
| + | |||
| + | Utility for debugging. It converts the alignment to the fusion junction library from bowtie output to [[#Breakpoint Data Format(BP)|BP]]. | ||
| + | |||
| + | '''Usage''': | ||
| + | |||
| + | bowtie2bp | ||
| + | |||
| + | * Input: bowtie alignment file from STDIN | ||
| + | * Output: [[#Breakpoint Data Format(BP)|BP]] file to STDOUT. | ||
| + | |||
| + | <center>[[#top|Top]]</center> | ||
| + | |||
| + | =Auxiliary modules= | ||
| + | ==== gfr2images ==== | ||
| + | |||
| + | It generates a schematic illustration depicting which regions of the two genes are connected by PE reads. | ||
| + | |||
| + | '''Usage''': | ||
| + | |||
| + | gfr2images < fileIN.gfr | ||
| + | |||
| + | * Pre-requisite: the pairCount column should be present in the [[#Gene_Fusion_Report_(GFR)|GFR]] file. [[#gfrCountPairTypes|gfrCountPairTypes]] should be executed first. | ||
| + | * Inputs: [[#Gene_Fusion_Report_(GFR)|GFR]] from STDIN | ||
| + | * Outputs: JPEG images labeled SampleID_0000#.jpg, where '''SampleID''' is the unique identification of the fusion candidate present in the [[#Gene_Fusion_Report_(GFR)|GFR]] file. | ||
| + | |||
| + | <center>[[#top|Top]]</center> | ||
| + | |||
| + | ==== gfr2fasta ==== | ||
| + | |||
| + | It generates two fasta files, one for each gene, with the PE-reads connecting them | ||
| + | |||
| + | '''Usage''': | ||
| + | |||
| + | gfr2fasta < fileIN.gfr | ||
| + | |||
| + | * Inputs: [[#Gene_Fusion_Report_(GFR)|GFR]] from STDIN | ||
| + | * Outputs: * Outputs: FASTA files labeled SampleID_0000#_[1|2].fasta, where '''SampleID''' is the unique identification of the fusion candidate present in the [[#Gene_Fusion_Report_(GFR)|GFR]] file and [1|2] indicates which gene they correspond to. | ||
| + | |||
| + | <center>[[#top|Top]]</center> | ||
| + | |||
| + | ==== gfr2bed ==== | ||
| + | |||
| + | It generates two BED files of the fusion transcript reads; one per gene. | ||
| + | |||
| + | '''Usage''': | ||
| + | |||
| + | gfr2bed < fileIN.gfr | ||
| + | |||
| + | * Inputs: [[#Gene_Fusion_Report_(GFR)|GFR]] from STDIN | ||
| + | * Outputs: BED files labeled SampleID_0000#_[1|2].bed, where '''SampleID''' is the unique identification of the fusion candidate present in the [[#Gene_Fusion_Report_(GFR)|GFR]] file and [1|2] indicates which gene they correspond to. | ||
| + | |||
| + | |||
| + | <center>[[#top|Top]]</center> | ||
| + | |||
| + | ==== gfr2gff ==== | ||
| + | |||
| + | It generates a GFF file for all candidates on the same chromosome reporting all PE-reads for visualization in genome browsers such as UCSC. | ||
| + | |||
| + | '''Usage''': | ||
| + | |||
| + | gfr2gff < fileIN.gfr | ||
| + | |||
| + | * Inputs: [[#Gene_Fusion_Report_(GFR)|GFR]] from STDIN | ||
| + | * Outputs: GFF files labeled SampleID_0000#.gff, where '''SampleID''' is the unique identification of the fusion candidate present in the [[#Gene_Fusion_Report_(GFR)|GFR]] file. | ||
| + | |||
| + | <center>[[#top|Top]]</center> | ||
| + | |||
| + | ==== export2mrf ==== | ||
| + | |||
| + | It generates an MRF file from the export files of a Genome Analyzer II run. | ||
| + | |||
| + | '''Usage''': | ||
| + | |||
| + | export2mrf prefix file_1_export.txt file_2_export.txt > file.mrf | ||
| + | |||
| + | * Inputs: | ||
| + | ** prefix: the sample ID | ||
| + | ** file_1_export.txt: the export file for the first end | ||
| + | ** file_2_export.txt: the export file for the second end | ||
| + | * Outputs: | ||
| + | ** An [[RSEQtools#Mapped_Read_Format_.28MRF.29|MRF]] file with all the mapped reads to STDOUT | ||
| + | ** prefix_allReads.txt: the list of all the reads for the breakpoint analysis. Each line reports only a read | ||
| + | ** prefix.meta: a summary file (tab-delimited) including the total number of reads and the number of mapped reads. This file is a prerequisite for [[#gfrConfidenceValues|gfrConfidenceValues]]. | ||
| + | |||
| + | <center>[[#top|Top]]</center> | ||
| + | |||
| + | ==== gfrAddInfo ==== | ||
| + | |||
| + | It includes additional information about the fusion transcript candidates such as gene symbols and gene description. This is a pre-requisite for [[#gfrBlackListFilter|gfrBlackListFilter]] and [[#gfrAnnotationConsistencyFilter|gfrAnnotationConsistencyFilter]]. | ||
| + | |||
| + | '''Usage''': | ||
| + | |||
| + | gfrAddInfo < fileIN.gfr > fileOUT.gfr | ||
| + | |||
| + | * Pre-requisite: | ||
| + | ** An external file that includes all descriptive information about the annotation set. The format of this file should follow kgXref.txt (from UCSC). Indeed, we use kgXref.txt for human, however, this could be modified in [[#geneFusionConfig|geneFusionConfig]]. | ||
| + | * Input: | ||
| + | ** A [[#Gene Fusion Report (GFR)|GFR]] file from STDIN. | ||
| + | * Output: | ||
| + | ** A [[#Gene Fusion Report (GFR)|GFR]] file to STDOUT with 4 additional columns: | ||
| + | **# geneSymbolTranscript1 | ||
| + | **# geneSymbolTranscript2 | ||
| + | **# descriptionTranscript1 | ||
| + | **# descriptionTranscript2 | ||
| + | |||
| + | <center>[[#top|Top]]</center> | ||
| + | |||
| + | ====gfrCountPairTypes==== | ||
| + | |||
| + | It counts how many PE reads are assigned to each category, i.e. exon-exon, exon-intron, etc. This is used by the the CGI programs to summarize the statistics of the fusion candidate. | ||
| + | |||
| + | '''Usage''': | ||
| + | |||
| + | gfrCountPairTypes < fileIN.gfr > fileOUT.gfr | ||
| + | |||
| + | * Input: | ||
| + | ** A [[#Gene Fusion Report (GFR)|GFR]] file from STDIN. | ||
| + | * Output: | ||
| + | ** A [[#Gene Fusion Report (GFR)|GFR]] file to STDOUT with 1 additional column (pairCount). See [[#Gene Fusion Report (GFR)|GFR]] for a description of this field. | ||
| - | |||
<center>[[#top|Top]]</center> | <center>[[#top|Top]]</center> | ||
| - | |||
Latest revision as of 19:20, 14 July 2011
User documentation main
Contents
|
Data formats
FusionSeq use a few data formats to perform its operations.
Mapped Read Format (MRF)
This format is defined in the context of RSEQtools. More details can be found here.
Gene Fusion Report (GFR)
This file format defines the relevant information for each fusion transcript candidate. The rationale is that different filters can be applied to exclude “false positives” artificial fusions starting from an initial set. We also provide a parser that interprets this format allowing the user to propagate easily any changes to this format. For a given fusion candidate, involving gene A and gene B, the basic GFR format requires the following fields:
- the ID of the fusion candidate (id): typically it contains the sample name and a unique number separated by an underscore. The number is padded with zeros for consistency;
- SPER, DASPER and RESPER: scoring of the fusion candidate;
- Number of inter-transcript reads (numInter), i.e. the number of pairs having the ends mapped to the two genes;
- P-value of the insert size distribution analysis for the fusion transcript. Since we do not know the actual composition of the fusion transcript, we compute the p-value for both directions: AB (where gene A is upstream of gene B - pValueAB) and BA (where gene B is upstream of gene A -- pValueBA);
- Mean insert-size value of the minimal fusion transcript fragment. As before for the p-values, we compute both AB and BA versions (interMeanAB, interMeanBA);
- Number of intra-transcript reads for gene A (numIntra1) and gene B (numIntra2), respectively, i.e the number of pairs where both ends map to the same gene;
- The type of the fusion (fusionType): cis, when both genes are on the same chromosome, or trans, otherwise;
- Name(s) of the transcripts (nameTranscript): all the UCSC gene IDs of the isoforms of each gene in the annotation separated by the pipe symbol '|';
- Chromosome of the genes (chromosomeTranscript);
- Strand information (strandTranscript);
- Start and end coordinates of the longest transcript for both genes (startTranscript, endTranscript);
- Number of exons in the composite model for both genes (numExonTranscript);
- Coordinates of the exons in the composite model (exonCoordinatesTranscript): each exon is separated by the pipe symbol '|' and start and end coordinates are comma-separated;
- Exon-pair count: it describes which elements are connected and corresponding number of inter-transcript reads;
- interReads: the pair-read type, as well as the exons and the coordinates of the reads joining the two genes. Pair-type, exon number, start and end coordinates are reported as a comma-separated list, with the pipe symbol '|' separating the different pairs. The pair-reads type encodes the different possibilities two reads can be classified to in terms of the gene annotation set:
- 1 : exon-exon
- 2 : exon-intron
- 3 : intron-exon
- 4 : intron-intron
- 5 : intron-boundary
- 6 : exon-boundary
- 7 : boundary-exon
- 8 : boundary-intron
- 9 : boundary-boundary
- Reads of the transcripts: the actual sequence of all the inter-reads.
- Pair-count: a summary of the number of reads for each category and joined exons (see interReads for the category definition). The field reports the pair-reads type, the number of reads, the two exons that are joined by the pair as a comma-separated list. The different pair types are separated by the pipe "|" symbol.
The GFR format can include additional optional information computed in the subsequent processing. For example, it is possible to add gene symbols (geneSymbolTranscript) and descriptions (descriptionTranscript) from the UCSC knownGene annotation set.
Breakpoint data format (BP)
Similarly to GFR, the junction-sequence identifier uses a standard format to capture the results of this analysis. For each tile that has at least 1 read aligned to, it reports, comma-separated:
- chromosome, start and end coordinates of the first tile, using UCSC notation: “chr:start-end”, although the intervals are 1-based and closed;
- chromosome, start and end coordinates of the second tile
- All the sequences of the reads mapped to that tile with the offset information, separated by the pipe symbol.
For example, one line may read as:
chr21:38764851-38764892,chr21:41758661-41758702,31:GTAGAATCATTCATTTCATTCTTGCAAACCAGCCTGCTTGGCCAGGAGGCA|30:TGTAGAATCATTCATTTCATTCTTGCAAACCAGCCTGCTTGGCCAGGAGGC
where two reads support this specific junction.
Core programs
Fusion detection module
geneFusions
geneFusions identifies potential fusion transcript candidates from an alignment file.
Usage:
geneFusions prefix minNumberOfReads < sample.mrf > fusions.gfr
- Inputs: Takes an MRF file from STDIN
- Outputs: Reports GFR to STDOUT
- Required arguments
- prefix - the main ID of each candidate, i.e. prefix_0001, prefix_0002, etc.
- minNumberOfReads - the minimum number of reads required to include a candiate
- Optional arguments
- none
Note: sample.mrf must include the sequences of the reads.
gfrClassify
gfrClassify assign each fusion candidate to a specify category: inter-, intra-chromosomal, read-through, or cis. Please see the publication for a description of these classes.
Usage:
gfrClassify < fileIN.gfr > fileOUT.gfr
Filtration cascade module
Mis-alignment filters
gfrLargeScaleHomologyFilter
It removes potential fusion transcript candidates if the two genes are paralogs. It uses TreeFam to establish is two genes have similar sequences.
Usage:
gfrLargeScaleHomologyFilter < fileIN.gfr > fileOUT.gfr
gfrSmallScaleHomologyFilter
It removes candidates that have high-similarity between small regions within the two genes, where the reads actually map.
Usage:
gfrSmallScaleHomologyFilter < fileIN.gfr > fileOUT.gfr
gfrRepeatMaskerFilter
Some reads may be aligned to repetitive regions in the genome, due to the low sequence complexity of those regions and may result in artificial fusion candidates. This filter removes reads mapped to those regions. If the number of reads left if less than a threshold, the candidate is removed.
Usage:
gfrRepeatMaskerFilter repeatMasker.interval minNumberOfReads < fileIN.gfr > fileOUT.gfr
- Inputs: GFR from STDIN
- Outputs: Reports GFR to STDOUT
- Required arguments
- repeatMasker.interval - the interval file with the coordinates of the repetitive regions
- minNumberOfRead - minimum number of reads overlapping the repetitive regions in order to remove the candidate
Random pairing of transcript fragments
gfrAbnormalInsertSizeFilter
gfrAbnormalInsertSizeFilter removes candidates with an insert-size bigger than the normal insert-size. The fusion candidate insert-size is computed on the minimal fusion transcript fragment.
Usage:
gfrAbnormalInsertSizeFilter pvalueCutOff < fileIN.gfr > fileOUT.gfr
- Inputs: GFR from STDIN
- Outputs: Reports GFR to STDOUT
- Required arguments
- pvalueCutOff - the p-value threshold above which we keep the fusion transcript candidates
Combination of mis-alignment and random pairing
gfrRibosomalFilter
gfrRibosomalFilter removes candidates that have similarity with ribosomal genes. The rationale is that reads coming from highly expressed genes, such as ribosomal genes, are more likely to be mis-aligned and assigned to a different genes.
Usage:
gfrRibosomalFilter < fileIN.gfr > fileOUT.gfr
gfrExpressionConsistencyFilter
It removes candidates that have a higher number of chimeric PE reads than PE reads aligned to the corresponding individual genes. This filter would only consider cases where the chimeric reads are mapped to introns of the two genes.
Usage:
gfrExpressionConsistencyFilter < fileIN.gfr > fileOUT.gfr
Other filters
gfrPCRFilter
gfrPCRFilter removes candidates with the same read over-represented, yielding to a “spike-in-like” signal, i.e. a narrow signal with a high peak.
Usage:
gfrPCRFilter offsetCutoff minNumUniqueRead
- Inputs: GFR from STDIN
- Outputs: Reports GFR to STDOUT
- Required arguments
- offsetCutoff - the minimum number of different starting positions
- minNumUniqueRead - the minimum number of unique reads required to include a candidate
gfrAnnotationConsistencyFilter
It removes candidates involving genes with specific description, such as ribosomal, pseudogenes, etc.
Usage:
gfrAnnotationConsistencyFilter string < fileIN.gfr > fileOUT.gfr
- Inputs: GFR from STDIN
- Outputs: Reports GFR to STDOUT
- Required arguments
- string - a string identifying the element to remove, ex. pseudogene
gfrProximityFilter
It removes candidates that are likely due to mis-annotation of the 5' or 3' ends of the genes.
Usage:
gfrProximityFilter offset < fileIN.gfr > fileOUT.gfr
- Inputs: GFR from STDIN
- Outputs: Reports GFR to STDOUT
- Required arguments
- offset - the minimum distance (in nucleotides) between the two genes to keep the candidate
gfrBlackListFilter
It removes candidates specified by the user in a file
Usage:
gfrBlackListFilter blackList.txt < fileIN.gfr > fileOUT.gfr
- Inputs: GFR from STDIN
- Outputs: Reports GFR to STDOUT
- Required arguments
- blackList.txt - the file with the candidates to remove. The format of this files is a simple two-column tab-delimited file with describing the two gene symbols. For example:
LOC388160 LOC388161 LOC388161 LOC388161 LOC440498 LOC440498
gfrSpliceJunctionFilter
It removes candidates if the reads can be aligned to a splice junction library. NB: this filter should be used only if the alignment was not performed against a splice junction library.
Usage:
gfrSpliceJunctionFilter splice_junction_library < fileIN.gfr > fileOUT.gfr
- Inputs: GFR from STDIN
- Outputs: Reports GFR to STDOUT
- Required arguments
- splice_junction_library - the splice_junction_library in 2bit format
gfrMitochondrialFilter
It removes candidates including a mitochondrial gene. NB: this filter should be used only if the alignment was performed against a gene annotation set with mitochondrial genes.
Usage:
gfrMitochondrialFilter < fileIN.gfr > fileOUT.gfr
Scoring the candidates
gfrConfidenceValues
gfrConfidenceValues computes the scores SPER, DASPER, and RESPER for each candidate. SPER is the number of Supportive PE Reads per candidates, i.e. the normalized number of inter-transcript reads.
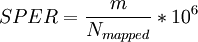
where m is the number of inter-transcript reads, i.e. PE-reads connecting two different genes.
DASPER (Difference between the observed and the Analytically computed SPER) and RESPER (Ratio between the observed SPER and the Empirically computed SPER) compare the observed SPER with two slightly different ways to compute the expectation. Please find at Genome Biology, 2010;11:R104 more information about those scores.
Usage:
gfrConfidenceValues prefix
- Input: GFR from STDIN
- Output: Reports GFR to STDOUT
- Required arguments
- prefix - the prefix of the .meta file
Note: gfrConfidenceValues expects that the file prefix.meta is available. This tab-delimited file includes some meta information about the MRF dataset. The minimum required set of information is the number of mapped reads with the following syntax as an example:
Mapped_reads 236549456
This represent the number of PE reads that were mapped. It is possible to determine this number by counting the number of lines in the MRF file. For example:
grep -v AlignmentBlocks file.mrf | grep -v "#" | wc -l
A one-line command to generate this is:
$ MAPPED=$(grep -v "AlignmentBlock" file.mrf | grep -v "#" | wc -l); printf "Mapped_reads\t%d\n" $MAPPED > file.meta
gfrConfidenceValueTranscript [deprecated]
gfrConfidenceValueTranscript computes LSPER (Local SPER) as the number of inter-transcript PE reads supporting the fusion divided by the average gene expression value. However, since in many cases, only one allele contributes to the fusion transcript, the expression of the fusion transcript may not correlate with the expression of the genes generating it. Please find at Genome Biology 2010;11:R104 more details about why this score may impair the correct ranking of the candidates (see Additional file 1, text and Figure S6).
Usage:
gfrConfidenceValueTranscript prefix
- Input: GFR from STDIN
- Output: Reports GFR to STDOUT
- Required arguments
- prefix - the prefix of the .composite.expression file
Note: gfrConfidenceValueTranscript expects that the file prefix.composite.expression is available. This file includes the expression values for the genes that are part of the transcript. The best way to compute is by using RSEQtools, using mrfQuantifier, e.g.:
mrfQuantifier knownGeneTranscriptCompositeModel.txt multipleOverlap < prefix.mrf > prefix.composite.expression
where knowGeneTranscriptCompositeModel.txt is the interval file representing the UCSC knownGenes library.
Junction-sequence identification module
gfr2bpJunctions
It generates the splice junction library and two files to be run with a cluster to perform the indexing and the mapping in parallel.
Usage:
gfr2bpJunctions <file.gfr> <tileSize> <sizeFlankingRegion> <minDASPER>
- Input: file.gfr - GFR file (not from STDIN)
- Outputs: Two files with all the jobs to be run on a cluster:
- file_joblist1.txt: the instructions to index the library and align the reads to the junction library.
- file_joblist2.txt: the instructions to aggregate the results of the alignment.
- Required parameters:
- tileSize: the number of nucleotides in each tile. For example, a 50nt read may be aligned to a 80nt junction, thus tileSize would be 40.
- sizeFlankingRegions: the size, in nucleotides, of the flanking region around the exons.
- minDASPER: the minimum DASPER values for which the breakpoint analysis is performed.
validateBpJunctions
It validates the junctions, i.e. excludes those junctions with sequence similarity to the other regions of the genome.
Usage:
validateBpJunctions < fileIN.bp > fileOUT.bp
bpFilter
It filters some of the junctions because of number of reasons (see parameters).
Usage:
bpFilter <minNumReads> <minNumUniqueOffsets> <minNumReadsForKS> <pValueCutoffForKS> <numPossibleOffsets>
- Input: BP file from STDIN
- Output: BP file to STDOUT
- Required parameters
- minNumReads: minimum number of reads aligned to the junction to be kept
- minNumUniqueOffsets: minimum number of unique reads aligned to the junction to avoid PCR artifacts
- minNumReadsForKS: minimum number of reads to perform a Kolmogorov-Smirnov (KS) test. This would compare the reads distribution with a uniform one. However, only if there are sufficient reads this test can be performed.
- pValueCutoffForKS: the pvalue cut-off if a KS test is used
- numPossibleOffsets: number of possible offsets, i.e. starting positions of the reads
bp2wig
It generates a signal track from the reads aligned to the junction.
Usage:
bp2wig file.bp
- Input: BP file (not from STIDIN)
- Output: WIGGLE files showing the support of the junction
bp2alignment
It generates a text representation of the reads aligned to the junction.
Usage:
bp2alignment
- Input: BP file from STDIN
- Output: an text file to STDOUT reporting the aligned read to the junction. For example:
Tile 1: chr21:38717312-38717353
Tile 2: chr21:41801877-41801918
Number of reads spanning breakpoint: 5
AGGAGGGTTC CTGCCGCGCTCCAGGCGGCGCTCCCCGCCCCTCGCCCTCCG
ATTCATCAGGAGAGTTC CTACCGCGCTCCAGGCGGCGCTCCCCGCCCCTCG
CCACACTGCATTCATCAGGAGAGTTC CTGCCGCGCTCCAGGCGGCGCTCCC
CTTCCCGCCTTCGGCCACACTGCATTCATCAGGAGAGTTC CTGCCGCGCTC
CTTCCCGCCTTCGGCCACACTGCATTCATCAGGAGAGTTC CTGCCGCGCTC
TCTTCCCGCCTTTGGCCACACTGCATTCATCAGGAGAGTTC CTGCCGCGCTCCAGGCGGCGCTCCCCGCCCCTCGCCCTCCG
bowtie2bp
Utility for debugging. It converts the alignment to the fusion junction library from bowtie output to BP.
Usage:
bowtie2bp
- Input: bowtie alignment file from STDIN
- Output: BP file to STDOUT.
Auxiliary modules
gfr2images
It generates a schematic illustration depicting which regions of the two genes are connected by PE reads.
Usage:
gfr2images < fileIN.gfr
- Pre-requisite: the pairCount column should be present in the GFR file. gfrCountPairTypes should be executed first.
- Inputs: GFR from STDIN
- Outputs: JPEG images labeled SampleID_0000#.jpg, where SampleID is the unique identification of the fusion candidate present in the GFR file.
gfr2fasta
It generates two fasta files, one for each gene, with the PE-reads connecting them
Usage:
gfr2fasta < fileIN.gfr
- Inputs: GFR from STDIN
- Outputs: * Outputs: FASTA files labeled SampleID_0000#_[1|2].fasta, where SampleID is the unique identification of the fusion candidate present in the GFR file and [1|2] indicates which gene they correspond to.
gfr2bed
It generates two BED files of the fusion transcript reads; one per gene.
Usage:
gfr2bed < fileIN.gfr
- Inputs: GFR from STDIN
- Outputs: BED files labeled SampleID_0000#_[1|2].bed, where SampleID is the unique identification of the fusion candidate present in the GFR file and [1|2] indicates which gene they correspond to.
gfr2gff
It generates a GFF file for all candidates on the same chromosome reporting all PE-reads for visualization in genome browsers such as UCSC.
Usage:
gfr2gff < fileIN.gfr
- Inputs: GFR from STDIN
- Outputs: GFF files labeled SampleID_0000#.gff, where SampleID is the unique identification of the fusion candidate present in the GFR file.
export2mrf
It generates an MRF file from the export files of a Genome Analyzer II run.
Usage:
export2mrf prefix file_1_export.txt file_2_export.txt > file.mrf
- Inputs:
- prefix: the sample ID
- file_1_export.txt: the export file for the first end
- file_2_export.txt: the export file for the second end
- Outputs:
- An MRF file with all the mapped reads to STDOUT
- prefix_allReads.txt: the list of all the reads for the breakpoint analysis. Each line reports only a read
- prefix.meta: a summary file (tab-delimited) including the total number of reads and the number of mapped reads. This file is a prerequisite for gfrConfidenceValues.
gfrAddInfo
It includes additional information about the fusion transcript candidates such as gene symbols and gene description. This is a pre-requisite for gfrBlackListFilter and gfrAnnotationConsistencyFilter.
Usage:
gfrAddInfo < fileIN.gfr > fileOUT.gfr
- Pre-requisite:
- An external file that includes all descriptive information about the annotation set. The format of this file should follow kgXref.txt (from UCSC). Indeed, we use kgXref.txt for human, however, this could be modified in geneFusionConfig.
- Input:
- A GFR file from STDIN.
- Output:
- A GFR file to STDOUT with 4 additional columns:
- geneSymbolTranscript1
- geneSymbolTranscript2
- descriptionTranscript1
- descriptionTranscript2
- A GFR file to STDOUT with 4 additional columns:
gfrCountPairTypes
It counts how many PE reads are assigned to each category, i.e. exon-exon, exon-intron, etc. This is used by the the CGI programs to summarize the statistics of the fusion candidate.
Usage:
gfrCountPairTypes < fileIN.gfr > fileOUT.gfr
- Input:
- A GFR file from STDIN.
- Output:
